
Spring Bean

Spring Bean là một trong những yếu tố quan trọng nhất mà bất kỳ lập trình viên nào khi bắt đầu với Spring Framework cũng cần phải nắm vững. Được ví như “trái tim” của Spring, các Bean không chỉ đại diện cho những đối tượng mà ứng dụng của bạn sử dụng mà còn là nền tảng cho cơ chế Dependency Injection (DI) giúp giảm sự phụ thuộc giữa các lớp. Hiểu rõ Spring Bean sẽ giúp bạn dễ dàng xây dựng những ứng dụng linh hoạt, dễ bảo trì và mở rộng trong tương lai. Trong bài viết này, chúng ta sẽ cùng tìm hiểu về khái niệm, cách sử dụng và các đặc điểm nổi bật của Spring Bean.
I. Bean là gì
Trong Spring Framework, Bean là một đối tượng được quản lý bởi Spring IoC (Inversion of Control) Container. Nói cách khác, Bean đại diện cho một thành phần cụ thể trong ứng dụng mà Spring sẽ chịu trách nhiệm tạo, khởi tạo, quản lý vòng đời và hủy bỏ khi cần thiết. Việc quản lý Bean này giúp tách biệt việc cấu hình và tạo đối tượng ra khỏi phần logic nghiệp vụ, tuân thủ nguyên tắc Dependency Injection (DI) và Inversion of Control (IoC).
Để hiểu hơn về DI, IoC bạn có thể xem tại đây
Tại sao phải sử dụng Bean trong Spring Framework
Tự động quản lý vòng đời: Spring Container tự động quản lý vòng đời của các bean từ khởi tạo đến khi hủy, giúp lập trình viên không phải quan tâm đến việc khi nào tạo hay hủy đối tượng, từ đó tập trung hơn vào việc phát triển logic nghiệp vụ.
Quản lý phụ thuộc (Dependency Management): Với Dependency Injection, Spring cho phép các thành phần được liên kết với nhau mà không cần phụ thuộc trực tiếp. Điều này giảm thiểu sự phụ thuộc giữa các module, làm cho ứng dụng dễ dàng bảo trì và mở rộng hơn.
Đơn giản hóa cấu hình: Các bean trong Spring có thể được cấu hình trong file XML hoặc qua các annotation, giúp quản lý cấu hình trở nên trực quan và dễ dàng hơn.
Tái sử dụng thành phần: Bean có thể được tái sử dụng trong nhiều ứng dụng khác nhau. Việc quản lý bean qua container giúp dễ dàng quản lý và tái sử dụng các thành phần.
Tích hợp với các mô hình lập trình tiên tiến: Spring hỗ trợ lập trình hướng khía cạnh (AOP), lập trình hướng sự kiện, và nhiều tính năng tiên tiến khác, nhờ vào cơ chế quản lý bean hiệu quả.
Cách khai báo Bean trong Spring
1. Khai báo Bean bằng XML
Trong file cấu hình XML, bạn có thể khai báo bean như sau:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="myBean" class="com.example.MyClass">
<!-- Các thuộc tính cần inject -->
<property name="dependency" ref="anotherBean"/>
</bean>
<bean id="anotherBean" class="com.example.AnotherClass"/>
</beans>
2. Khai báo Bean bằng Annotation
Sử dụng annotation để khai báo bean là phương pháp phổ biến hơn vì nó đơn giản và ít rườm rà. Ví dụ:
package com.example;
import org.springframework.stereotype.Component;
@Component
public class MyClass {
// Class body
}@Component: Dùng để đánh dấu một class là một Bean. Spring sẽ tự động phát hiện và đăng ký vào ApplicationContext.
@Service, @Repository, @Controller: Là các annotation đặc thù cho tầng dịch vụ, truy cập dữ liệu, và controller, cũng được sử dụng để khai báo Bean.
3. Java-based Configuration
Bạn có thể sử dụng Java để cấu hình bean, thay vì sử dụng XML hoặc annotations một cách trực tiếp:
package com.example.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.example.MyClass;
@Configuration
public class AppConfig {
@Bean
public MyClass myClass() {
return new MyClass();
}
}
@Configuration: Đánh dấu class chứa cấu hình bean.
@Bean: Đánh dấu phương thức sẽ trả về một bean và được Spring quản lý.
II. Bean Scope
Trong Spring Framework, scope của một bean xác định phạm vi tồn tại của bean đó trong Spring Container. Nói cách khác, scope xác định thời điểm bean được tạo và có bao nhiêu instance của bean đó sẽ tồn tại trong suốt vòng đời của ứng dụng. Spring hỗ trợ nhiều loại scope khác nhau để tạo ra các instance cho các tình huống sử dụng khác nhau. Các scope cơ bản của Spring như hình bên dưới:
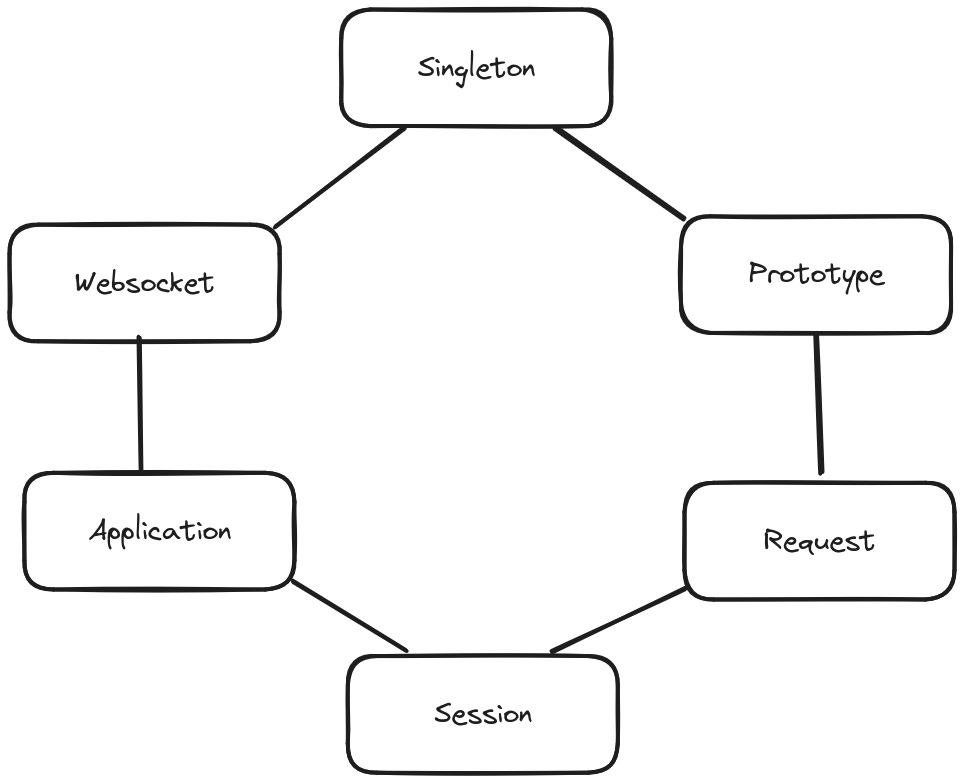
1. Singleton
Singleton Scope trong Spring định nghĩa rằng chỉ có một instance duy nhất của một bean được quản lý bởi Spring Container cho mỗi Application Context. Điều này có nghĩa là tất cả các yêu cầu cho bean với một ID cụ thể (tên bean) sẽ trả về cùng một đối tượng duy nhất đã được Spring Container tạo ra trước đó.
Cách hoạt động:
Khởi tạo bean: Khi ứng dụng khởi động, Spring Container sẽ tạo một instance duy nhất của các bean được đánh dấu với Singleton Scope theo cách bạn đã định nghĩa trong ApplicationContext.
Lưu trữ trong bộ nhớ: Instance của Singleton bean được lưu trữ trong bộ nhớ của Spring Container. Việc này đảm bảo rằng bạn có thể truy cập và sử dụng lại cùng một đối tượng từ bất kỳ đâu trong ứng dụng.
Tiếp tục sử dụng instance: Sau khi instance của Singleton bean được tạo ra và lưu trữ, container sẽ duy trì và quản lý nó trong suốt thời gian sống của ứng dụng. Bất kỳ lúc nào bạn yêu cầu bean thông qua dependency injection hoặc gọi phương thức getBean, container sẽ cung cấp lại cùng một instance.
Chia sẻ instance: Mọi thành phần hoặc các bean khác trong ứng dụng yêu cầu cùng một Singleton bean đều nhận được tham chiếu đến cùng một instance đã tồn tại. Điều này tạo điều kiện cho việc chia sẻ dữ liệu và tránh việc tạo ra nhiều bản sao của cùng một dữ liệu không cần thiết.
Vòng đời của bean: Singleton bean tồn tại từ khi ứng dụng bắt đầu chạy cho đến khi ứng dụng kết thúc. Bean này chỉ được tạo một lần duy nhất và được giữ lại trong suốt thời gian sống của ứng dụng, cho đến khi Spring Container bị hủy.
Những lưu ý khi sử dụng Singleton Scope:
1. Singleton Stateless
Tránh lưu trữ trạng thái (Statelessness): Singleton bean nên được thiết kế để không lưu trữ trạng thái nếu có thể. Điều này có nghĩa là dữ liệu trong bean không nên thay đổi theo thời gian và mọi thao tác trên bean đều dựa vào tham số đầu vào.
Ví dụ về Singleton Stateless
@Service public class UserService { public void createUser(String username, String email) { // Logic xử lý tạo user mà không lưu bất kỳ trạng thái nội bộ nào } public User getUserByEmail(String email) { // Trả về thông tin user dựa trên email mà không thay đổi trạng thái của bean } }Trong trường hợp này, UserService là một bean Singleton không lưu trữ trạng thái. Do đó, bạn có thể sử dụng nó trong các môi trường đa luồng mà không gặp vấn đề về tính đồng bộ (synchronization).
2. Thread Safety
Đảm bảo an toàn đối với đa luồng (Thread Safety): Nếu Singleton bean của bạn lưu trữ trạng thái, bạn cần phải đảm bảo rằng các thao tác trên dữ liệu trong bean đó được thực hiện một cách an toàn đối với đa luồng. Việc này thường đòi hỏi bạn phải sử dụng các cơ chế đồng bộ (synchronization) hoặc các công cụ quản lý song song (concurrency utilities) của Java như Atomic, synchronized hoặc ReadWriteLock.
Ví dụ Singleton Stateful:
@Service public class UserService { private final List<User> users = new ArrayList<>(); public synchronized void createUser(User user) { users.add(user); } public synchronized List<User> getAllUsers() { return new ArrayList<>(users); } }Trong ví dụ trên, UserService là một Singleton Stateful bean. Nó lưu trữ danh sách người dùng (stateful). Để tránh các vấn đề cạnh tranh (race condition), các phương thức createUser và getAllUsers cần phải được đánh dấu synchronized để đảm bảo tính an toàn đối với đa luồng.
3. Lazy Initialization
Khởi tạo lười biếng (Lazy Initialization): Đối với các Singleton bean tiêu tốn nhiều tài nguyên hoặc yêu cầu thời gian khởi tạo lâu, bạn có thể sử dụng @Lazy để chỉ định rằng bean này sẽ chỉ được khởi tạo khi nó thực sự cần thiết.
@Service @Lazy public class ExpensiveService { public ExpensiveService() { // Khởi tạo dịch vụ tốn nhiều tài nguyên } public void doSomething() { // Thực hiện một số công việc } }Việc sử dụng @Lazy sẽ giúp trì hoãn việc khởi tạo bean cho đến khi bạn thực sự yêu cầu nó, tiết kiệm tài nguyên và giảm thời gian khởi động ứng dụng.
2. Prototype
Prototype Scope là một scope đặc biệt, khác biệt hoàn toàn so với Singleton Scope. Khi một bean được định nghĩa với Prototype Scope, mỗi lần bạn yêu cầu bean đó, một instance hoàn toàn mới sẽ được tạo ra. Điều này có nghĩa rằng mỗi lần bạn yêu cầu bean, Spring sẽ cung cấp một đối tượng mới, hoàn toàn độc lập với các đối tượng trước đó và không chia sẻ dữ liệu giữa các instance.
Đặc điểm của Prototype Scope
1. Tạo mới mỗi lần yêu cầu
Với Prototype Scope, mỗi lần bạn yêu cầu một bean từ Spring Container, container sẽ tạo một instance mới của bean đó. Điều này đảm bảo rằng các instance không chia sẻ dữ liệu và không bị ảnh hưởng lẫn nhau.
2. Thời gian sống ngắn hơn
Các bean được định nghĩa với Prototype Scope có vòng đời ngắn hơn rất nhiều so với Singleton Scope. Chúng chỉ tồn tại từ thời điểm được yêu cầu cho đến khi sử dụng xong. Sau đó, bean sẽ bị hủy và thu hồi bởi Java Garbage Collector (GC).
3. Dữ liệu không được chia sẻ
Mỗi instance của bean đều có dữ liệu riêng, hoàn toàn độc lập với các instance khác hoặc bất kỳ bean nào khác trong ứng dụng. Điều này giúp giảm nguy cơ xảy ra xung đột hoặc các lỗi liên quan đến trạng thái dùng chung.
4. Tính linh hoạt cao hơn
Prototype Scope mang lại tính linh hoạt cao khi xử lý các tác vụ yêu cầu các đối tượng khác nhau cho mỗi lần chạy. Điều này đặc biệt hữu ích trong các tình huống xử lý request, tạo ra các đối tượng tạm thời hoặc mô phỏng các đối tượng test khác nhau trong môi trường thử nghiệm.
Cách hoạt động:
Khi bạn định nghĩa một bean với Prototype Scope, Spring sẽ không khởi tạo bean đó khi ứng dụng khởi động (trừ khi bạn thực sự yêu cầu nó thông qua dependency injection hoặc gọi getBean). Thay vào đó, Spring sẽ chỉ tạo một instance mới cho mỗi lần bạn gọi.
Những lưu ý khi sử dụng Prototype Scope
1. Không quản lý toàn bộ vòng đời của Prototype Bean
Một điểm cần lưu ý khi sử dụng Prototype Scope là Spring không quản lý toàn bộ vòng đời của bean. Khi bạn sử dụng Singleton Scope, Spring Container sẽ gọi các callback lifecycle (như @PreDestroy) khi đối tượng bị hủy. Tuy nhiên, với Prototype Scope, Spring chỉ quản lý việc tạo ra bean, nhưng không quản lý việc hủy nó. Do đó, bạn cần tự giải quyết vấn đề dọn dẹp tài nguyên cho các bean Prototype.
2. Sử dụng Prototype Scope một cách cân nhắc
Mặc dù Prototype Scope giúp tạo ra các đối tượng độc lập, nhưng nếu sử dụng không đúng cách có thể dẫn đến vấn đề về tài nguyên. Việc tạo mới liên tục các đối tượng Prototype sẽ gây tốn kém bộ nhớ và tài nguyên CPU, đặc biệt là với các đối tượng có trạng thái nặng (heavyweight).
Chỉ nên sử dụng Prototype Scope khi bạn thực sự cần một đối tượng độc lập với vòng đời ngắn và không cần tái sử dụng.
3. Inject Prototype vào Singleton
Khi bạn inject một bean Prototype vào một bean Singleton, bean Prototype vẫn sẽ được coi là một instance duy nhất trong toàn bộ vòng đời của bean Singleton. Điều này xảy ra vì bean Singleton chỉ được khởi tạo một lần và nó sẽ sử dụng cùng một instance của Prototype bean trong toàn bộ vòng đời của nó.
Giải pháp: Để giải quyết vấn đề này, bạn có thể sử dụng @Lookup annotation hoặc sử dụng ObjectFactory để tạo ra một đối tượng Prototype mới mỗi khi cần.
@Component public class SingletonBean { @Autowired private ObjectFactory<PrototypeBean> prototypeBeanFactory; public void showMessage() { PrototypeBean prototypeBean = prototypeBeanFactory.getObject(); System.out.println("Prototype Instance: " + prototypeBean); } }
3. Request Scope
Request Scope được sử dụng trong các ứng dụng web để xác định rằng một instance mới của bean sẽ được tạo cho mỗi request HTTP được gửi tới ứng dụng. Điều này đảm bảo rằng các bean với Request Scope chỉ tồn tại trong suốt quá trình xử lý một request cụ thể và sẽ được thu hồi sau khi request kết thúc. Mỗi yêu cầu mới sẽ nhận được một đối tượng độc lập, không liên quan đến các request trước hoặc sau đó.
Đặc điểm của Request Scope
Tạo mới cho mỗi request: Mỗi khi một request HTTP được gửi đến ứng dụng, một instance mới của Request Scope bean sẽ được tạo ra. Điều này đảm bảo rằng các instance không chia sẻ dữ liệu và không ảnh hưởng lẫn nhau giữa các request khác nhau.
Thời gian sống ngắn hạn: Bean chỉ tồn tại trong thời gian xử lý một request duy nhất và sẽ bị hủy ngay khi request kết thúc.
4. Session Scope
Session Scope được sử dụng để tạo ra một bean có thời gian sống gắn liền với một phiên làm việc (session) của người dùng. Điều này có nghĩa là mỗi phiên làm việc của người dùng sẽ có một instance riêng của Session Scope bean, đảm bảo rằng các dữ liệu không bị chia sẻ giữa các phiên làm việc khác nhau.
Đặc điểm của Session Scope
Tạo mới cho mỗi phiên làm việc: Khi một phiên làm việc (session) được bắt đầu, một instance mới của bean với Session Scope sẽ được tạo ra và tồn tại trong suốt phiên làm việc đó.
Thời gian sống trong suốt phiên làm việc: Các bean với Session Scope tồn tại từ khi phiên làm việc của người dùng bắt đầu cho đến khi phiên làm việc kết thúc. Điều này đảm bảo rằng dữ liệu được duy trì xuyên suốt phiên làm việc của người dùng.
Phù hợp cho dữ liệu liên quan đến phiên làm việc: Session Scope thích hợp cho các bean mà dữ liệu liên quan đến phiên làm việc của người dùng, chẳng hạn như lưu trữ thông tin đăng nhập, thông tin về giỏ hàng mua sắm hoặc các tham số tùy chỉnh của người dùng.
5. Application Scope
Application Scope xác định rằng một instance duy nhất của bean sẽ được tạo và chia sẻ trên toàn bộ ServletContext. Điều này có nghĩa là khi bean được khởi tạo, nó sẽ tồn tại trong suốt thời gian sống của ứng dụng và được chia sẻ giữa tất cả các request và session. Chỉ có một instance duy nhất được quản lý bởi Spring Container trong toàn bộ ứng dụng.
Đặc điểm của Application Scope
Chia sẻ toàn bộ ứng dụng: Application Scope cho phép một bean được chia sẻ giữa tất cả các thành phần của ứng dụng, bao gồm nhiều phiên người dùng và nhiều request khác nhau.
Thời gian sống dài hạn: Bean sẽ tồn tại cho đến khi ứng dụng được gỡ bỏ hoặc khởi động lại.
6. WebSocket Scope
WebSocket Scope gắn liền với vòng đời của WebSocket. Một bean được xác định trong phạm vi này sẽ tồn tại trong khoảng thời gian kết nối WebSocket và bị loại bỏ khi WebSocket bị đóng. Điều này có nghĩa là mỗi kết nối WebSocket sẽ có một bean riêng với WebSocket Scope.
Đặc điểm của WebSocket Scope
Tạo mới cho mỗi kết nối WebSocket: Mỗi khi một kết nối WebSocket được thiết lập, một instance mới của WebSocket Scope
beansẽ được tạo ra.Thời gian sống ngắn hạn: Bean tồn tại trong suốt thời gian của một kết nối WebSocket và bị hủy khi kết nối bị đóng.
III. Bean life cycle
Trong Spring Framework, Lifecycle của một bean liên quan đến quy trình tạo ra và hủy đi một bean trong một ứng dụng Spring. Quá trình này bao gồm các bước quan trọng mà một bean đi qua từ khi nó được tạo ra đến khi nó bị hủy bỏ. Lifecycle của bean trong Spring được quản lý bởi container Spring, và nó cho phép can thiệp vào các giai đoạn khác nhau của vòng đời của bean để thực hiện các tác vụ tùy chỉnh.
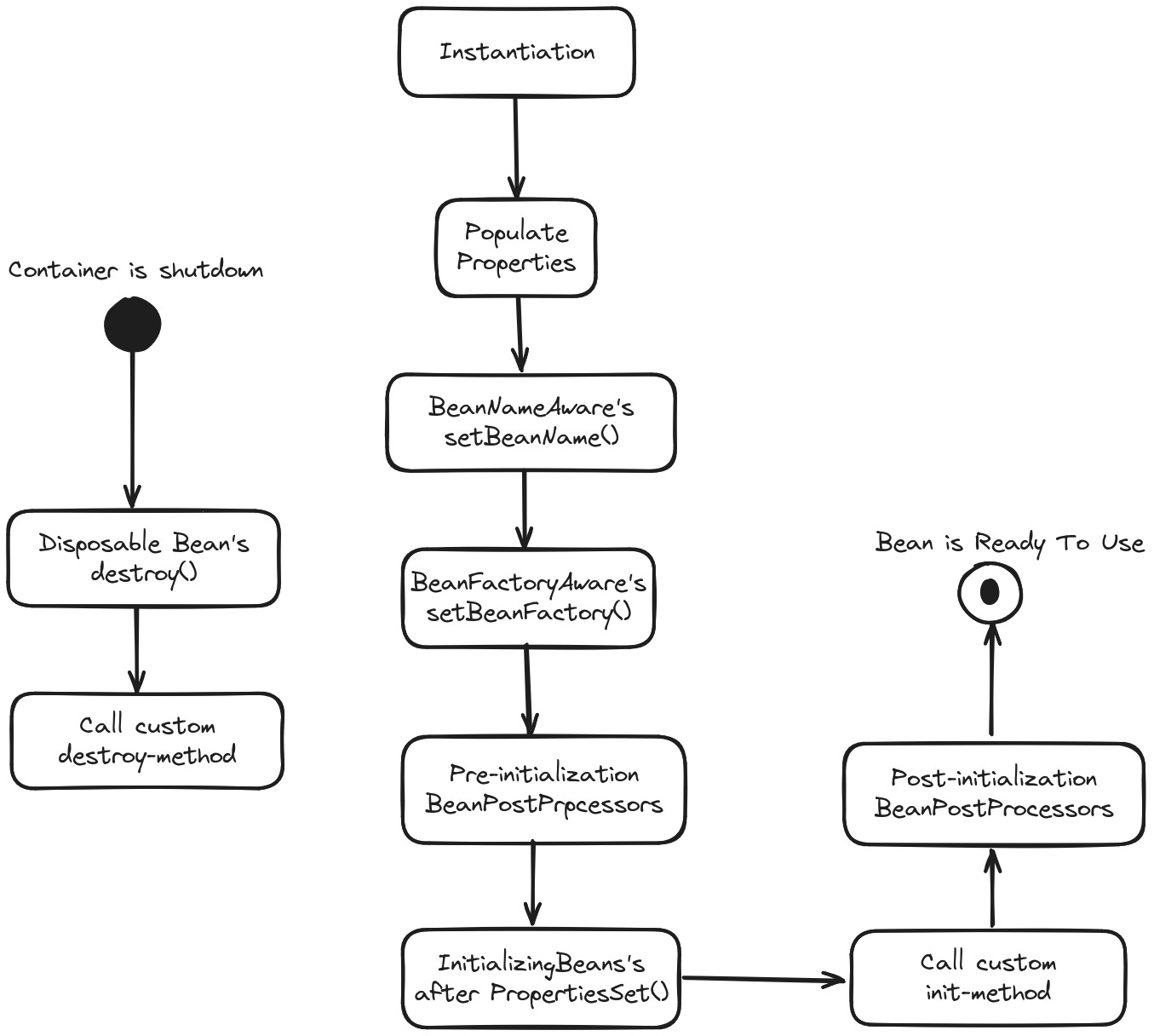
Về cơ bản ta có thể chia ra làm 2 phases chính như hình các bạn thấy:
Bean Creation Phases
1. Giai Đoạn Khởi Tạo Bean (Instantiation)
Đây là giai đoạn đầu tiên trong vòng đời của một Bean, nơi mà Spring Container sẽ tạo ra một instance (thể hiện) của Bean. Spring khởi tạo các đối tượng Bean giống như cách chúng ta tạo một đối tượng Java theo cách thủ công bằng cách sử dụng từ khóa new hoặc thông qua các constructor được định nghĩa.
Nếu Bean được định nghĩa thông qua một Factory Method hoặc Factory Bean, Spring sẽ sử dụng phương thức khởi tạo tương ứng để tạo đối tượng Bean.
2. Giai Đoạn Thiết Lập Thuộc Tính (Populating Properties)
Sau khi Bean được khởi tạo, Spring sẽ tiến hành thiết lập các thuộc tính cho Bean bằng cách sử dụng cơ chế Dependency Injection. Việc này bao gồm việc cung cấp các giá trị đã được định nghĩa trong tệp cấu hình hoặc thông qua @Autowired, @Value, hoặc các cơ chế khác.
Ngoài ra, ở bước này, Spring sẽ quét qua các Bean implement các interface thuộc nhóm Aware, cho phép Bean nhận được các thông tin liên quan như BeanName, BeanFactory hoặc ApplicationContext.
Các Interface Aware Phổ Biến:
BeanNameAware: Nếu Bean triển khai interface BeanNameAware, Spring sẽ gọi phương thức setBeanName() để cung cấp một tham chiếu đến tên (ID) của Bean trong Spring Container.
public class MyBean implements BeanNameAware { @Override public void setBeanName(String beanName) { System.out.println("Tên của Bean: " + beanName); } }BeanFactoryAware: Nếu Bean triển khai interface BeanFactoryAware, Spring sẽ gọi phương thức setBeanFactory() để cung cấp một tham chiếu đến BeanFactory hiện tại.
public class MyBean implements BeanFactoryAware { @Override public void setBeanFactory(BeanFactory beanFactory) { System.out.println("BeanFactory đã được thiết lập."); } }ApplicationContextAware: Nếu Bean triển khai interface ApplicationContextAware, Spring sẽ gọi phương thức setApplicationContext() để cung cấp một tham chiếu đến ApplicationContext hiện tại.
public class MyBean implements ApplicationContextAware { @Override public void setApplicationContext(ApplicationContext context) { System.out.println("ApplicationContext đã được thiết lập."); } }
3. Giai Đoạn Tiền Khởi Tạo (Pre-Initialization)
Ở giai đoạn này, các BeanPostProcessor sẽ được kích hoạt và thực hiện các tác vụ tùy chỉnh cho Bean trước khi nó được khởi tạo hoàn toàn. BeanPostProcessor là một interface quan trọng cho phép bạn can thiệp vào vòng đời của Bean trước và sau khi các phương thức khởi tạo được thực hiện.
Các phương thức postProcessBeforeInitialization() được gọi trong giai đoạn này để thực hiện các tác vụ tùy chỉnh, như kiểm tra và cấu hình các thuộc tính đặc biệt của Bean.
Các Phương Thức Quan Trọng trong BeanPostProcessor:
postProcessBeforeInitialization(Object bean, String beanName):
Phương thức này được gọi trước khi Bean được khởi tạo hoàn toàn.
Bạn có thể thực hiện các tác vụ tùy chỉnh trước khi Bean hoàn toàn khởi tạo, như thiết lập các giá trị mặc định hoặc kiểm tra tính hợp lệ của Bean.
postProcessAfterInitialization(Object bean, String beanName):
Phương thức này được gọi sau khi Bean đã được khởi tạo hoàn toàn.
Bạn có thể sử dụng phương thức này để thêm các hành vi tùy chỉnh sau khi Bean đã sẵn sàng hoạt động.
4. Giai Đoạn Thiết Lập Sau Khởi Tạo (AfterPropertiesSet)
Sau khi các thuộc tính đã được thiết lập và các BeanPostProcessor đã hoàn thành, Spring sẽ kiểm tra xem Bean có triển khai interface InitializingBean hay không. Nếu có, phương thức afterPropertiesSet() sẽ được gọi để cho phép bạn thực hiện các tác vụ khởi tạo bổ sung.
public class MyBean implements InitializingBean {
@Override
public void afterPropertiesSet() {
System.out.println("Các thuộc tính đã được thiết lập");
}
}
5. Giai Đoạn Khởi Tạo Tùy Chỉnh (Custom Initialization)
Trong giai đoạn này, các phương thức tùy chỉnh sẽ được gọi bằng cách sử dụng các annotation như @PostConstruct hoặc thông qua các phương thức được khai báo trong cấu hình XML với thuộc tính init-method. Đây là nơi bạn có thể thực hiện các tác vụ khởi tạo tùy chỉnh mà bạn muốn áp dụng cho Bean trước khi nó sẵn sàng hoạt động.
@Component
public class MyBean {
@PostConstruct
public void customInit() {
System.out.println("Phương thức khởi tạo tùy chỉnh được gọi");
}
}
6. Giai Đoạn Hậu Khởi Tạo (Post-Initialization)
Ở giai đoạn này, BeanPostProcessor của Spring hoạt động lần thứ hai để thực thi các tác vụ sau khi Bean đã được khởi tạo hoàn toàn. Điều này đảm bảo rằng mọi quá trình khởi tạo của Bean đều đã hoàn thành và Bean sẵn sàng được sử dụng.
Các phương thức postProcessAfterInitialization() sẽ được gọi để thực hiện các hành vi tùy chỉnh hoặc kiểm tra cuối cùng trước khi Bean đi vào hoạt động.
Bean Destruction Phases
1. Giai Đoạn Trước Hủy (Pre-Destroy)
Pre-Destroy là giai đoạn chuẩn bị trước khi Bean bị hủy thực sự. Ở giai đoạn này, bạn có thể thực hiện các công việc như:
Đóng các kết nối mở (database, file, socket).
Dọn dẹp các tài nguyên đang sử dụng.
Lưu trữ trạng thái hoặc thực hiện các tác vụ cần thiết trước khi Bean không còn tồn tại trong bộ nhớ.
Spring cho phép bạn sử dụng annotation @PreDestroy để đánh dấu một phương thức sẽ được gọi trong giai đoạn Pre-Destroy. Phương thức này sẽ được gọi trước khi Bean thực sự bị hủy.
@Component
public class ResourceBean {
// Giả sử có một kết nối database cần đóng trước khi hủy bean
private Connection connection;
@PreDestroy
public void preDestroy() {
System.out.println("Giai đoạn Pre-Destroy: Đóng kết nối và dọn dẹp tài nguyên.");
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
Trong ví dụ trên, phương thức preDestroy() sẽ được gọi trước khi ResourceBean bị hủy để đảm bảo rằng tất cả các kết nối cơ sở dữ liệu đã được đóng một cách an toàn.
2. Giai Đoạn Hủy (Destroy)
Destroy là giai đoạn mà Bean được đánh dấu là sẵn sàng để bị loại bỏ khỏi Spring Container. Sau khi các tác vụ chuẩn bị trong giai đoạn Pre-Destroy đã hoàn thành, Spring sẽ thực hiện hủy đối tượng Bean.
3. Giai Đoạn Hủy Tùy Chỉnh (Custom Destruction)
Custom Destruction cho phép bạn định nghĩa các phương thức tùy chỉnh để thực hiện các tác vụ hủy đặc biệt trước khi một Bean bị loại bỏ khỏi Spring Container. Đây là giai đoạn mà bạn có thể tùy chỉnh quá trình hủy Bean theo nhu cầu của ứng dụng như:
Đóng kết nối với các dịch vụ bên ngoài.
Giải phóng các tài nguyên đặc biệt (như bộ nhớ tạm, thread pools).
Ghi lại log hoặc thực hiện các công việc cleanup cuối cùng.
Với việc hiểu rõ khái niệm Bean, các Scope Bean phổ biến và vòng đời của chúng, chúng ta đã nắm vững nền tảng quan trọng để làm chủ Spring Framework. Hy vọng rằng những kiến thức này sẽ giúp bạn tối ưu hóa quy trình phát triển và khai thác hiệu quả sức mạnh của Spring trong các dự án thực tế của mình. Hãy đón chờ những bài blog tiếp theo về Spring Framework nhé!